ReidenXerx, у разработчика с Гитхаба возьми: https://github.com/Yoti/AnalogsEnhancer/releases
Там UTF-8 без бома. Причём одной строкой, без переноса строки.
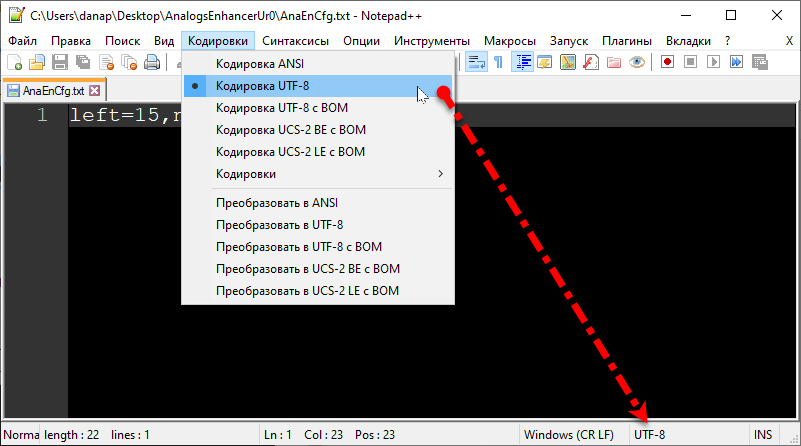
И редактируют такие документы, конечно же не в блокноте и не во всяких Word-подобных фигулинах, а в текстовом редакторе Notepad++. - Собственно, если в тексте только английские символы, то это конечно на самом деле однобайтная кодировка ANSI. Она и в UTF-8 находится на том же месте, поэтому так отображает у меня по умолчанию.
- А вот если в тексте написать хотя бы одну букву из другой кодировки, например русскую букву, тогда, при сохранении в UTF-8, так же и все английские символы сохранятся в двубайтной кодировке, что уже программой будет читаться уж точно не как ANSI.
- И метка BOM имеет значение, при этом записывается в начало текстовика 2 дополнительных символа, указывающие программам, в какой кодировке текстовик.
Так что такие моменты нужно учитывать. Программы могут на этом спотыкаться и не так обрабатывать строки, не как было задумано разработчиком.
Последний раз редактировалось ErikPshat; 05.01.2021 в 06:19.
|